Are you ready to take your French language learning to the next level? Explore the captivating world of French cinema with our comprehensive culture unit designed for French 3 students and beyond. Whether you’re teaching in-person or remotely, this versatile unit is packed with engaging materials to spark students’ curiosity and deepen their understanding of French film history, from its early beginnings to the influential New Wave movement of the 1960s.
Our French Cinéma Unit takes students on a fascinating journey through the evolution of French film, providing rich insights into its cultural significance and artistic innovations. With a focus on culture and civilization, this unit is perfect for educators seeking to integrate authentic cultural content into their language curriculum.
Comprehensive PowerPoint Presentations: Dive into French cinema history with our detailed PowerPoint presentations, covering everything from the early pioneers of French filmmaking to the revolutionary New Wave movement.
Engaging Readings with Questions: Explore key themes and developments in French cinema through a series of carefully curated readings, accompanied by thought-provoking questions and answer keys for easy assessment.
Visual Resources and Examples: Enhance students’ understanding of cinematic techniques and styles with visual resources, including examples of New Wave filming techniques and iconic scenes from classic French films.
Online Access to Vocabulary Studies and Etudes: Provide students with remote access to vocabulary studies and interactive activities through our virtual classroom platform at InnovationAssessments.com/TestDrive. With auto-corrected questions embedded in the lessons, students can track their progress and engage with the material in a dynamic way.
Take Learning Beyond the Classroom: Empower your students to become active participants in their language learning journey with our French Cinéma Unit. Whether in the classroom or online, this comprehensive resource offers a wealth of opportunities for students to explore, analyze, and appreciate French culture through the lens of cinema.
Get Started Today: Ready to dive into the captivating world of French cinema? Visit our store on Teachers Pay Teachers to access our French Cinéma Unit and transform your language curriculum today! With engaging materials, comprehensive resources, and online access to vocabulary studies, this unit is sure to inspire and engage your students on their French language learning journey.
Unlock the magic of French cinema. Ignite your students’ passion for language and culture. Explore the French Cinéma Unit today!
Are you looking for an innovative and engaging essay prompt to enrich your American history curriculum? Look no further! Our unique essay prompt invites students to delve into key moments and themes in U.S. history through the analysis of primary source documents. Designed for educators teaching U.S. history at grade 11, this prompt provides a stimulating opportunity for students to explore, analyze, and interpret primary sources while honing their historical inquiry and critical thinking skills.
Our essay prompt challenges students to explore the constitutional and civic issue of civil rights and racial equality in early American history. Through the analysis of four carefully selected primary source documents, students will:
Document 1: Excerpt from a contract recording the sale of land along the Hudson River from Mahican Indians to Kiliaen van Rensselaer, 1630.
Document 2: Image of Paul Revere’s drawing of the Boston Massacre.
Document 3: Excerpt from a confidential letter, Jefferson’s message to Congress on the Expedition West.
Document 4: Bartolomé de las Casas — Excerpts from The Very Brief Relation of the Devastation of the Indies.
Document 5: Jefferson’s “original Rough draught” of the Declaration of Independence, 1776.
Document 6: A traveler describes life along the Erie Canal, 1829.
Engage Students in Active Learning: This essay prompt is designed to engage students in active learning experiences that foster historical inquiry, critical analysis, and historical literacy. By examining primary source documents, students will gain a deeper understanding of the complexities, contradictions, and enduring struggles that have shaped America’s constitutional and civic landscape.
Passcodes for Online Versions in my virtual classroom at Innovation Website
Give your students the passcodes to access online auto-corrected versions of the lessons in this unit. If you are a subscriber toInnovation, you can use the passcodes to import the activities into your own account and test banks. You can see and save student work that way. If not, just have your students send you a screenshot of their score on completing the task.
Enhance Classroom Instruction: Integrate this essay prompt into your history curriculum to:
Stimulate student interest and curiosity in key moments and themes in American history.
Encourage students to analyze and interpret primary sources, strengthening their analytical and research skills.
Foster meaningful class discussions and debates on issues of civil rights, racial equality, and social justice.
Provide students with opportunities to develop their written communication skills through the composition of well-reasoned and evidence-based essays.
Unlock the Past with Teachers Pay Teachers: Access our engaging essay prompt today on Teachers Pay Teachers. Whether you’re a history teacher seeking to inspire critical thinking and historical inquiry or a homeschooling parent looking for thought-provoking curriculum materials, our essay prompt offers a valuable tool for bringing American history to life in your classroom or homeschool environment.
Don’t miss out on this opportunity to empower your students to become active participants in the study of history. Visit our store on Teachers Pay Teachers to download our essay prompt and ignite a passion for historical inquiry and critical thinking in your students today!
Embark on a captivating journey through French heritage with our immersive culture unit tailored for French 3 students and beyond. Rooted in a pedagogical approach that emphasizes cultural exploration, this comprehensive package offers an in-depth exploration of France’s rich architectural and intangible heritage. Crafted with both in-person and remote learning in mind, our adaptable materials provide educators with the flexibility to seamlessly integrate cultural studies into their curriculum, whether in print or online.
Dive into the essence of French patrimoine with our three meticulously designed PowerPoint presentations, totaling 31 slides, covering architectural marvels and intangible cultural artifacts. Enhance vocabulary acquisition with our tier 2 word list, thoughtfully curated to facilitate reading comprehension and linguistic fluency. Immerse yourself in the captivating world of French heritage through four engaging readings complemented by comprehension questions, as well as thought-provoking inquiries tailored for six enlightening videos. Additionally, ignite students’ creativity and critical thinking with two composition assignments designed to deepen their understanding and appreciation of French cultural heritage. Plus, gain exclusive access to our virtual classroom at Innovation, where students can further explore and engage with the rich tapestry of French patrimoine. Elevate your French language curriculum and inspire a deeper connection to French culture with our dynamic and comprehensive French Heritage “Patrimoine” Unit.
Short Essay Prompts, New York State Regents US History and Government
Unlocking America’s Past: An Exploration of Historical Documents
Join us on a journey through America’s dynamic history with our two groundbreaking products designed to enhance historical document analysis skills and deepen understanding of pivotal periods in American history.
Delve into the transformative era of 19th-century America with our meticulously curated collection of primary sources. Engage in critical analysis as you explore letters from pioneering women activists like Elizabeth Cady Stanton, alongside Senate debates on the Kansas-Nebraska Act. Our comprehensive set includes scoring rubrics, sample student essays, and exclusive access to video lessons with embedded auto-corrected questions. Uncover the voices of change and gain insights into the struggles for equality and justice that shaped the nation.
Documents:
Elizabeth Cady Stanton to Susan B. Anthony
Excerpt from the Senate Debate on the Kansas-Nebraska Act, 1854
Excerpt from the Virginia Resolution, 1798
William Lloyd Garrison Introduces The Liberator, 1831
Explore the complexities of post-Civil War America with our comprehensive resource focusing on Reconstruction policies and the rise of Jim Crow laws. Analyze primary sources such as the Semi-annual report on schools for freedom, and a newspaper article from the Richmond planet. Gain a deeper understanding of the socio-political landscape through documents like Charles Sumner’s address on the power struggle between the President and Congress, and an excerpt from the Mississippi Black Code. With scoring rubrics, sample student essays, and video lessons, uncover the nuances of America’s evolution during this transformative period.
Documents:
Semi-annual report on schools for freedom, 1866
Newspaper Article in the Richmond planet, 15 September 1900, Page 8
“One Man Power vs. Congress” address, Charles Sumner (Mass.), Boston 2 October 1866
Excerpt, Mississippi Black Code (1865)
Immerse yourself in America’s past and unlock the complexities of its history with our engaging and comprehensive educational resources. Visit our blog to learn more about our teaching methods and how these products can elevate your classroom experience.
Step into the flavorful world of French culinary heritage with our captivating culture unit designed for French 3 and beyond. Developed by an experienced educator who prioritizes cultural immersion in language learning, this product offers an enriching exploration of France’s gastronomic traditions. Whether teaching in-person or remotely, our comprehensive materials cater to both environments, ensuring flexibility and accessibility for educators and students alike.
Delve into the nuances of French dining etiquette and culinary history with meticulously crafted PowerPoints, “A Table” and “Patrimoine culinaire,” featuring engaging visuals and informative content spread across 46 slides. Expand vocabulary acquisition with our tier 2 word list, carefully curated to enhance reading comprehension and fluency. Engage in immersive learning experiences with five captivating readings accompanied by comprehension questions, along with thought-provoking inquiries tailored for six culinary and etiquette-focused videos. Additionally, ignite students’ creativity and linguistic prowess with two composition assignments designed to foster critical thinking and cultural appreciation. Plus, gain exclusive access to our virtual classroom at Innovation, where students can further immerse themselves in the rich tapestry of French culture. Elevate your French language curriculum and ignite a passion for cultural exploration with our dynamic and comprehensive French culinary heritage unit.
Using translation with beginner language students is fraught with controversy. When I was in elementary school, the contemporary teaching methods for modern languages were phasing out from “grammar-translation” toward more communicative approaches. Translation came to be seen as antiquated, impractical, unnatural.
It cannot be denied that some criticism of translation, especially for beginners, is valid. I cannot help reflect on some brilliant students I have had over the years who, by French III, had become held back by their insistence on mentally translating everything before they wrote or spoke. Their focus on the rules, the words, the syntax, the burden of feeling like they must not err, all conspired to leave them tongue-tied and frozen whenever they were called upon to improvise speech or writing.
Nonetheless, I find in my experience that there is a place for translation in novice language lessons. Students should learn the ways that the target language differs from their own so that they gradually learn to avoid applying the syntactical patterns of their own language. The also need to be able to discern morphological differences in the target language that may be slight to their eyes but which meaning can vary significantly. Finally, it is a good way for novices to learn the longer, whole functional phrases that are a part of the earliest stages of learning before grammar has been taught to let them synthesize their own utterances.
Barriers to Using Translation to Teach Novices
Limited vocabulary is the first barrier to using translation to teach novices. In the textbooks at the start of the 20th century, each chapter had a very controlled vocabulary that was repeated in reading and translation exercises. Many of us no longer teach that way. I teach through theme units. The unit has a lot of vocabulary but the higher order language work is not limited to that as a controlled vocabulary list. Narratives and authentic texts, even listening practices, while selected with difficulty in mind, do in fact include words and structures the student may not yet have been taught. The advantages of this approach are well known and it is common practice now. Among other things, the student learns the very functional skill of deriving meaning from context, selectively ignoring incomprehensible utterances in favor of the meaningful, and perhaps learning new words from context.
The second barrier to teaching with translation is, naturally, grammar. Good grammar exercises that use translation have to be very controlled to account for irregulars and inconsistencies that most language boast of. At the very early stages, novices has so little grammar under their belt that translation may not prove worthwhile. Or, the cognitive load of balancing all the rules will render the exercise useless for its purpose.
Here is What I Needed
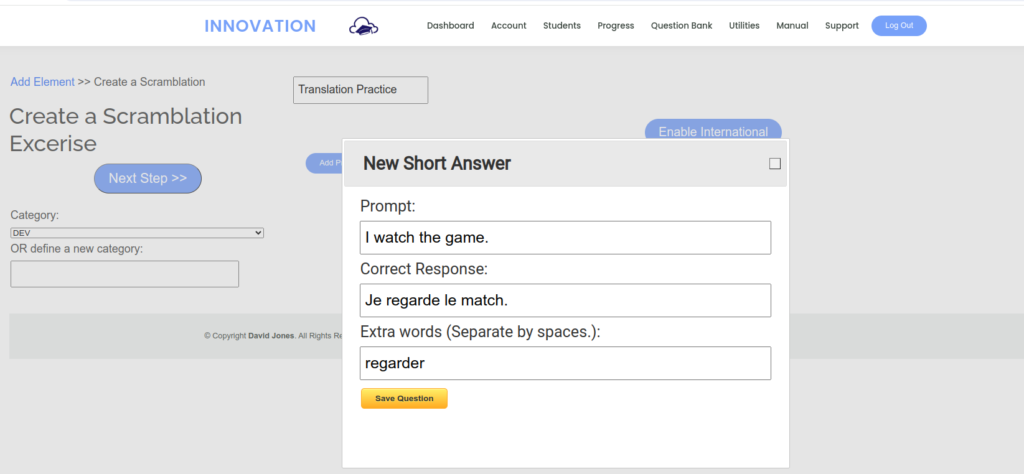
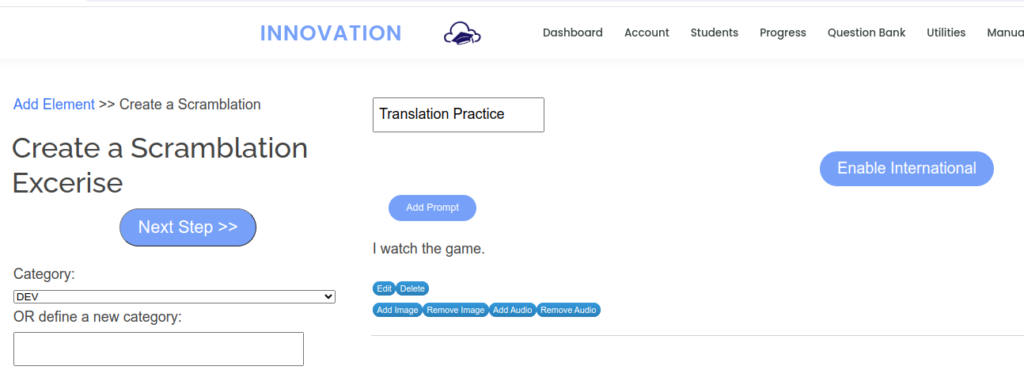
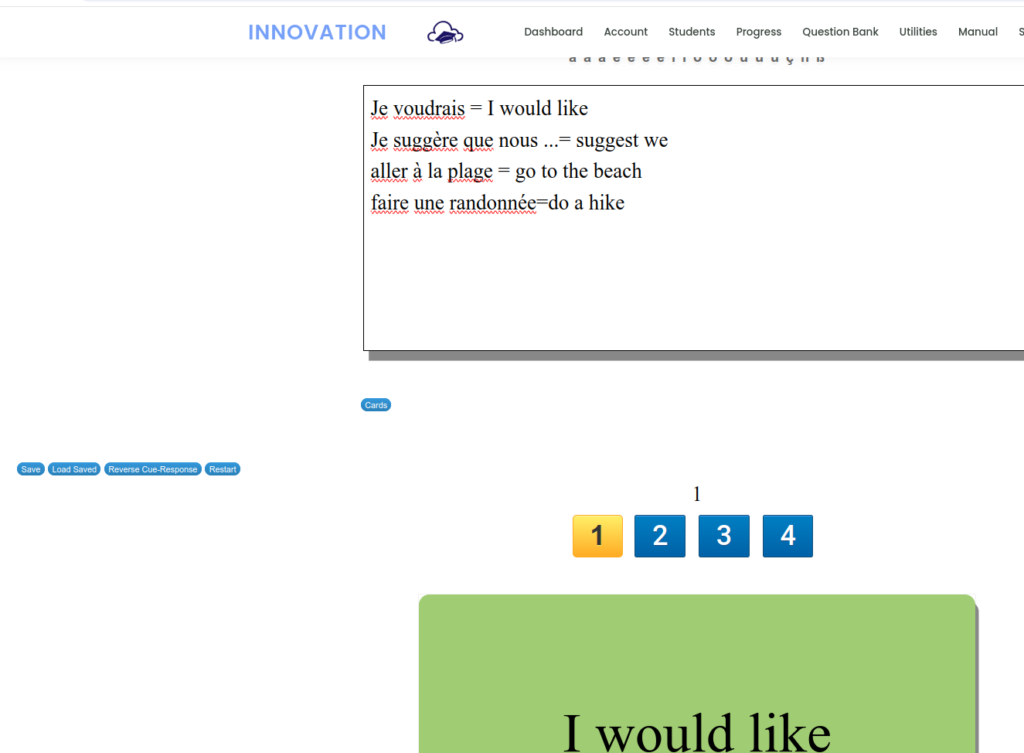
I needed an app that would auto-correct and let students try again when they made errors. I needed limited vocabulary and limited grammatical competence to be largely irrelevant. I needed an interactive activity where students manage the syntax and recognize correct forms. I call the new app “scramblation”. It is a drag-and-drop interface where students assemble an utterance in the target language from a prompt that is either in text form or audio clip.
Translation plays a pivotal role in the process of studying a foreign language, serving as a valuable tool for language learners to bridge the gap between their native tongue and the target language. It offers learners a nuanced understanding of linguistic structures, idiomatic expressions, and cultural nuances, thereby facilitating a more profound comprehension of the language’s intricacies. Translating texts from the target language to one’s native language and vice versa enhances vocabulary acquisition, grammar proficiency, and overall language competence. It enables learners to decipher the meaning behind words and phrases, fostering a deeper connection to the cultural context embedded within the language. Moreover, translation exercises encourage critical thinking and analytical skills, as learners must carefully consider the nuances of each word and construct coherent and contextually accurate sentences.
A New App
Instructors can generate a new scramblation from the playlist of their course in Innovation. They enter a prompt, the correct answer, and some extra words. I link to use the extra words to enter un-conjugated verbs or words an English speaker might put in that would not go in the target language.
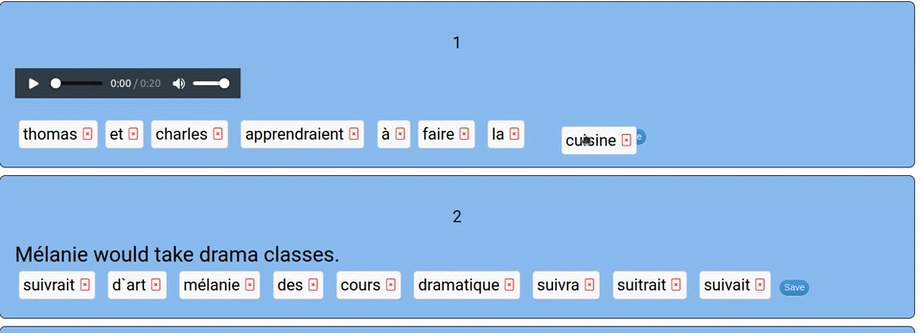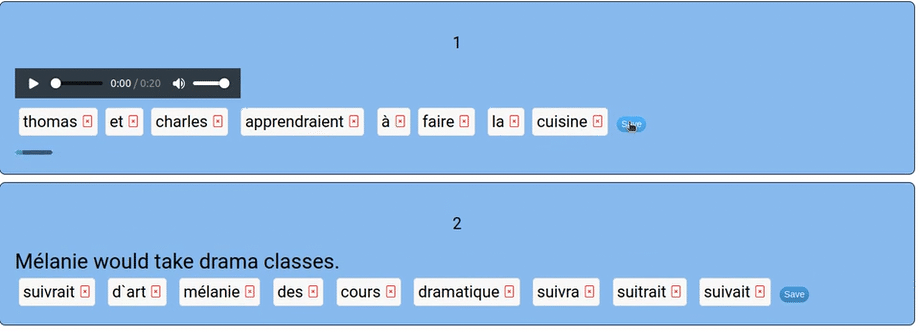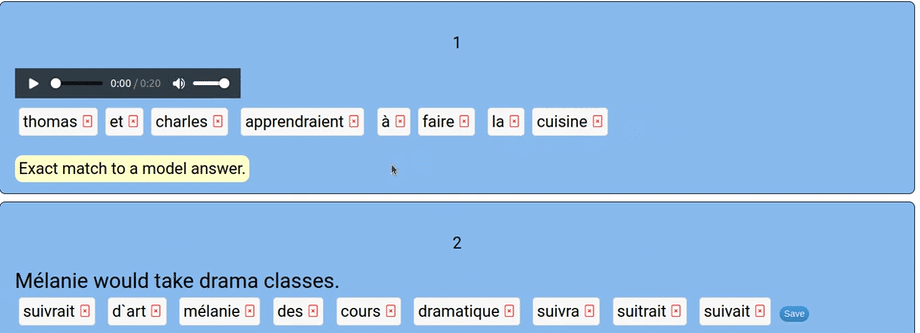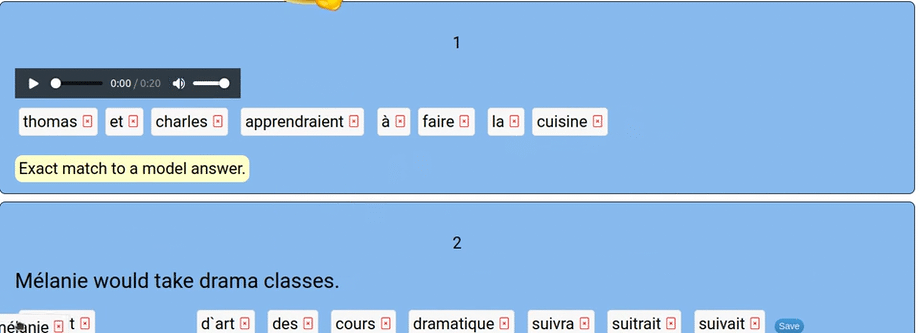
The prompt can be an audio clip (in which case the text prompt is hidden) and can include an image.
Students can see the task in their playlist and access to a scramblation can be made possible from a link in the lesson plan app or an external link that instructors can send to students.
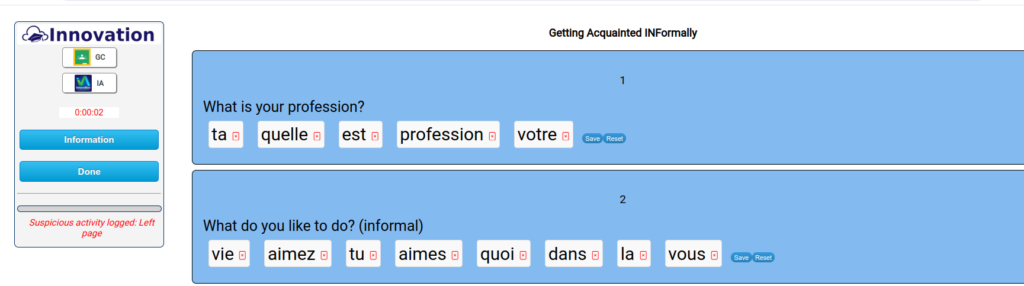
The app itself is simple: first, students should remove any extra words by clicking the small red “x” in the word’s box. Next, the student drags and drops the words into the right order. They save their answer, check it, and the algorithmic AI will tell them how close they are.
Like all of the apps at Innovation, the scramblation has a proctor activated that tracks student activity on the page, including when they leave the page and how long they were working.
The importance of interactive web applications in the realm of remote teaching cannot be overstated. Interactive web applications emerge as powerful catalysts for student engagement, collaboration, and personalized learning experiences. The ability to seamlessly integrate multimedia content, real-time communication, and interactive assessments not only enhances the effectiveness of teaching but also empowers educators to adapt their pedagogical approaches to the diverse needs of their students.
I submit two new “Enduring Issue” essay prompt modeled on the New Regents examinations in New York State. This Enduring Issue Essay presents the students with five documents, from which they select three to support some enduring issue they see through history.
Both products include access to video lessons with embedded questions here at Innovation so your students can review the historical context before writing their analysis.
When empires start to crumble, the “group feeling” that Ibn Khaldun noted as the binding force of society begins to unravel. In the face of the stress of migrations, invasions, internal political polarization, economic distress there comes a disintegration of morals and customs of courtesy. This does not go unnoticed by everyone. In Of Decadence and Empire’s Fall, students explore primary sources from the Roman Empire and the Han Dynasty. They may see the warnings from the wise about a decline in moral behavior. They may piece together similar contributing factors to the disintegration of a political unit.
Document excerpts included in this essay prompt:
Excerpt, The Conspiracy of Catiline, Gaius Sallustius Crispus, 63 BCE
Excerpt, Sima Qian and Laissez-Faire:Manifestations of a “Discordant and Degenerate Age”
Excerpt, St. Jerome, “Letter 127: To Principia”, 412CE
Excerpt, A Translation of the Chronicle on the ‘Western Regions’ from the Hou Hanshu, the dynastic history of the Han dynasty
Painting, The Course of Empire: Destruction (1836) by Thomas Cole
Those of us who have taught high school for decades are well acquainted with adolescent rebelliousness. Frankly, I respect it, I expect it, and I wonder about the young person who is not a little instinctively resistant. Be that said, I know that I am usually right anyway. : )
When the proportion of young in the population gets high, such as in Iran in the late ’70s and the US when the Baby Boomers came to late teens, you can bet there will be social upheaval! In “On Students in Revolt”, students in Global Studies 10 (New York State curriculum) will examine primary sources related to times in history when students were the impetus for change. These are not generally positive, which I hope does not reveal a middle aged bias on my part.
Document excerpts included in this essay prompt:
Report by Louis P. Lochner, Head of the Berlin Bureau of the Associated Press (10 May 1933)
Mr. Dai, a sociologist in Beijing, attended Tsinghua University High School, where the first Red Guard groups were formed.
On the Hostages’ Release, AFP Press Release, 14 January 1980
The key drawback to early efforts at distance learning was being kind of trapped behind that camera like a goldfish in a bowl. You could make all the signs and signals you wanted, but the world on the other side of the glass was beyond your ability to control.
Teaching remotely is not highly effective when it consists of essentially just holding up things to the camera for the student to experience. Activate the Zoom – Skype – Meet – Teams session, share your PDF, give verbal instructions… this is a weak instructional practice mainly because it is largely passive for the student.
If the teacher were in a real classroom, tutoring the student at an honest-to-goodness table, the learning materials could be manipulated in real life in ways that support the process. They can fold the paper to hide the answer, they can shuffle the flash cards, they can write and cross out and scribble and erase. The manipulation of the learning materials is important.
The apps at Innovation are designed to promote the kind of virtual interactivity that heightens the effectiveness of teaching remotely. To be a great learning experience, the remote session needs to be virtually interactive in the same effective way that in-person lessons are. This is a big part of what we mean by the “21st century learning space”.
Flashcards
Let’s take up the example of teaching vocabulary using flashcards. In real life, I would want to use a process whereby I selectively show the student a new word, rehearse the pronunciation in some meaningful way, then cue up the words to rehearse the meanings.
Using the passive approach, I could share a PDF through the video conference software and “go over” the list with the student.
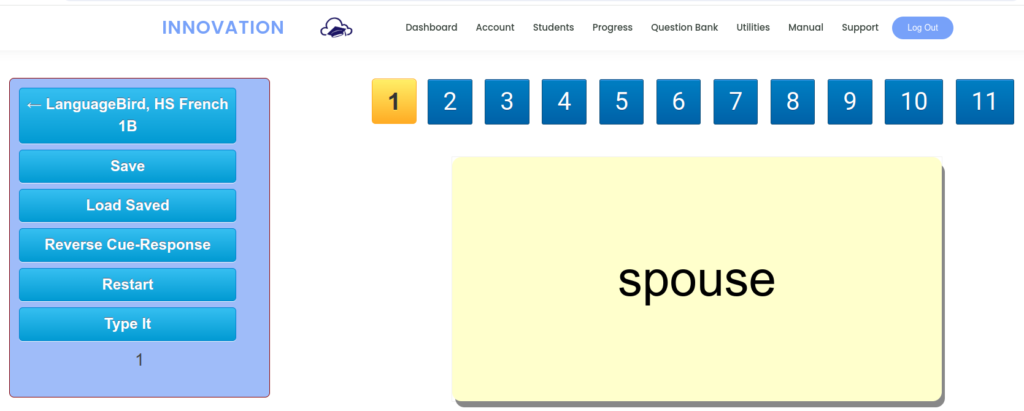
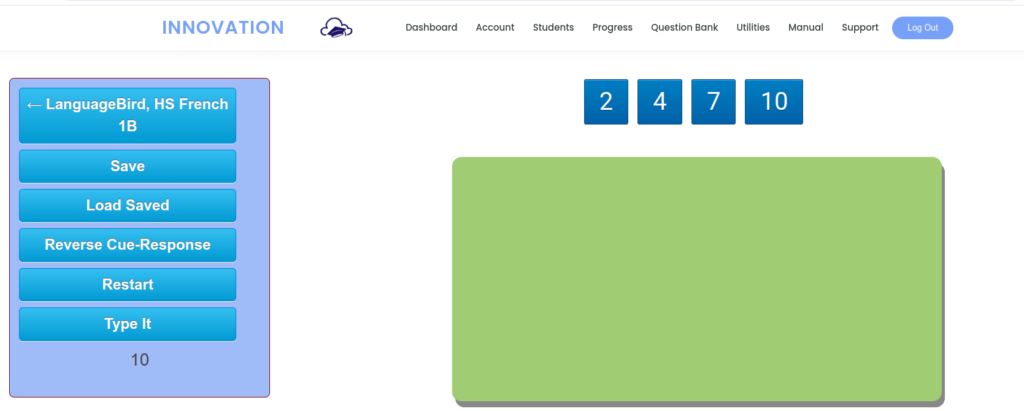
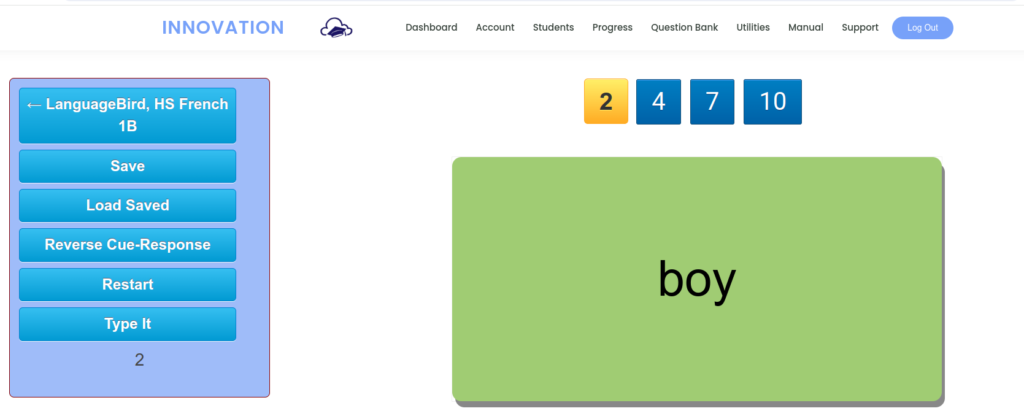
Using the flashcard app at Innovation, I can interact so much more effectively. To begin, I can select the target vocabulary word to display.
I prompt the student to repeat the pronunciation, then click to reveal the meaning.
Once we are through the list, I can repeat the process, only this time I can save out those items the student forgot.
Now we are only drilling those items. We can talk about mnemonic devices, use the words in sentences, or just repeat and rehearse. Once the student has the words down pat for recognition, I click Reverse Cue-Response to prompt from English cue.
Integrated Flashcard App
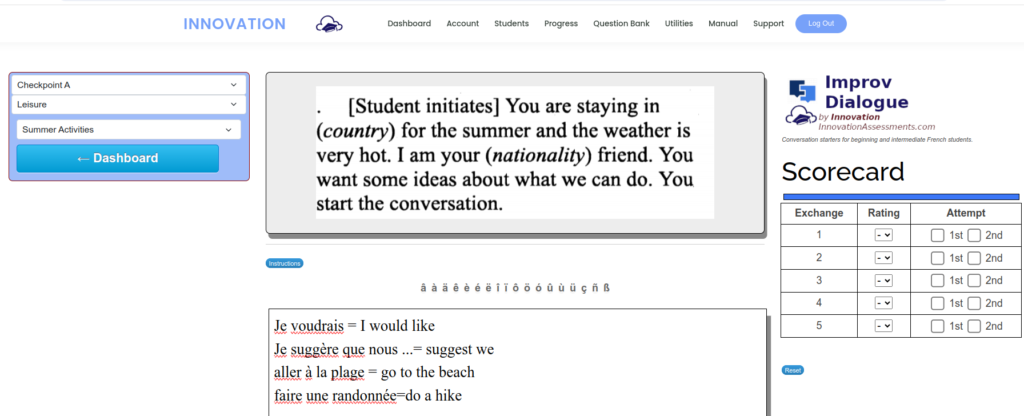
The improvised conversation app and the scaffold dialogue app both have integrated flashcards. During an improvised conversation task, the student may need to ask me how to say some words as we run through the conversation the first time. I list them for them in the textarea below the prompt.
So long as I pair the new phrases with an equal sign and a meaning, the app can generate a flashcard system right underneath after our conversation.
We can rehearse now the new words and phrases before we perform the dialogue once again.
Interactivity is Key
Being able to interact virtually over remote teaching sessions in ways that are as effective as in-person is absolutely necessary to achieve a satisfying learning experience that maximizes our effective use of time. The flashcard app at Innovation facilitates this process of simple cue-response training that is so foundational in teaching language. It allows me to go beyond just sharing my screen to “go over” a PDF!
Innovation has developed some very effective applications for teaching world languages remotely or in a classroom with a student 1:1 laptop configuration. I have been teaching French remotely for a few months now and have had the opportunity to really take these apps out for a rigorous test drive and to make some great tweaks under the hood!
Regents Global 9 Enduring Issue Essay Prompt: Belief Systems
This particular enduring theme essay began as an exploration of the idea that spiritual leaders in history often had “wilderness experiences” as part of their own religious awakening. This is the best-selling enduring issue essay prompt product from our store at TeacherPayTeachers that I would like to showcase today.
The enduring issue essay is a task in the curriculum and state testing in New York State for Global History and Geography. Students examine a set of documents and compose an essay making the case for an enduring historical issue that they observe, combining documents and their knowledge of the historical context.
Documents 1-4 of this prompt are selections from religious texts giving evidence for the following: Jesus’ forty days in the desert and subsequent temptation, Buddha’s temptation by Mara in the forest, Muhammad’s visits to the cave where he receives the revelation from the angel Jibreel, Joseph Smith’s walk in the 1832 New York woods to meet Jesus. Document 5 is a map of Abraham’s journey from the Torah.
Strictly speaking, the Regents enduring essay task will be something a bit different from this. However, the theme works nicely in a unit on the world’s belief systems.
When I developed this task, I did have one common theme in mind to start, however students may see others, which I illustrate in the sample student essays included in the product.
This enormous project also includes a modified version of the readings for special education purposes as well as a complete collection of video lessons on belief systems. These video lessons include embedded, auto-corrected questions to guide practice.
I invite the reader to peruse our store and explore the other thought-provoking document-based essay prompts we offer! Support great scholarship with quality materials!