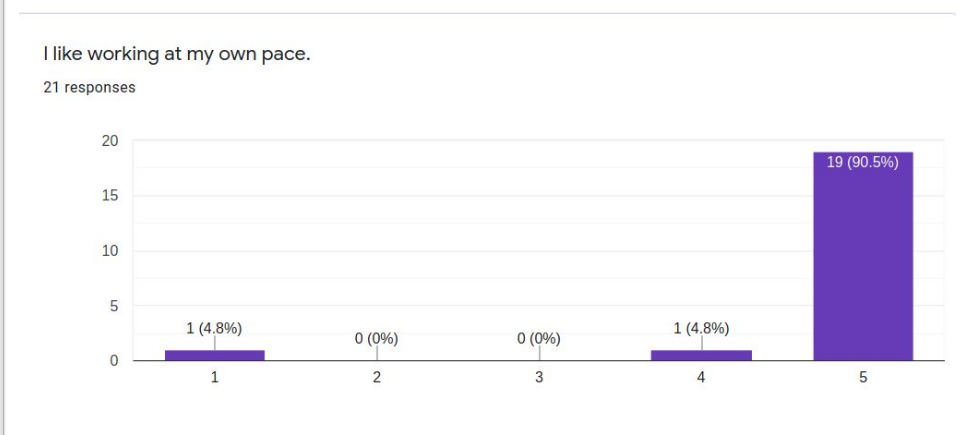
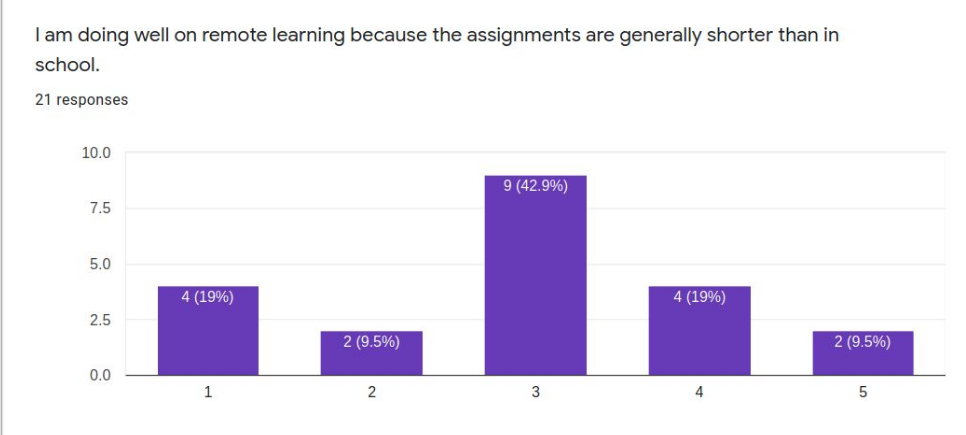
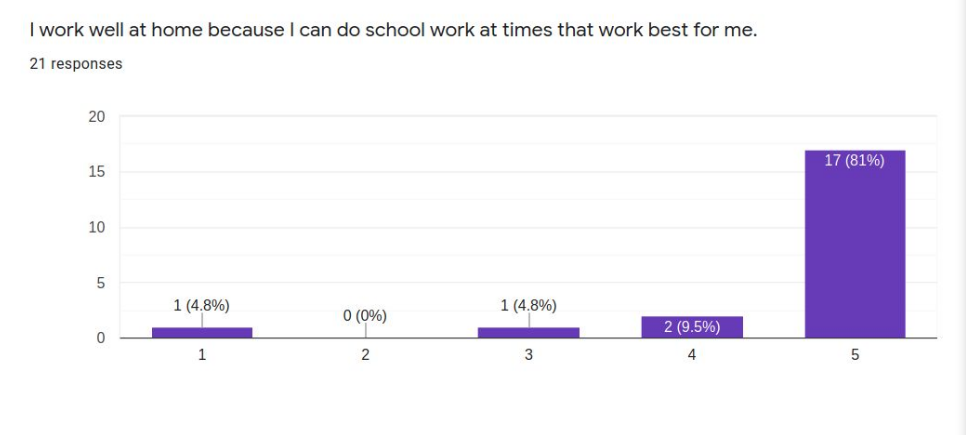
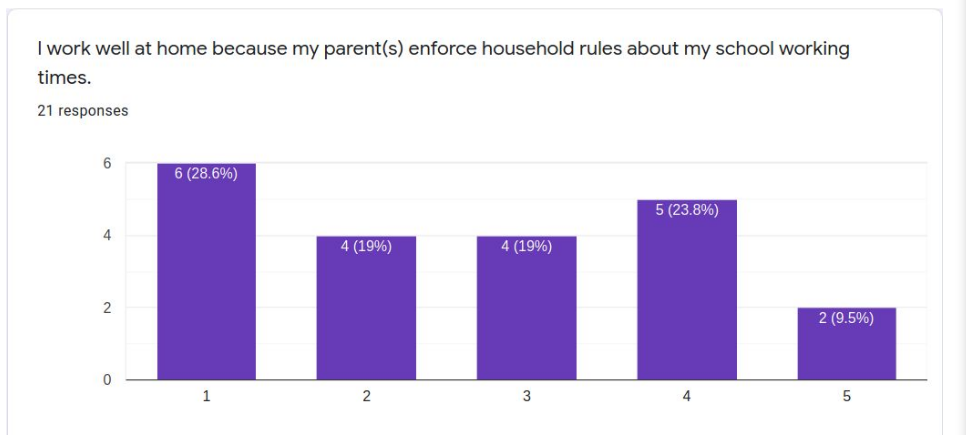
In mid-May 2020, we were finishing up 2 months of remote learning during the pandemic. I conducted a study to find out what I could learn from the students who were very successful learning online remotely.
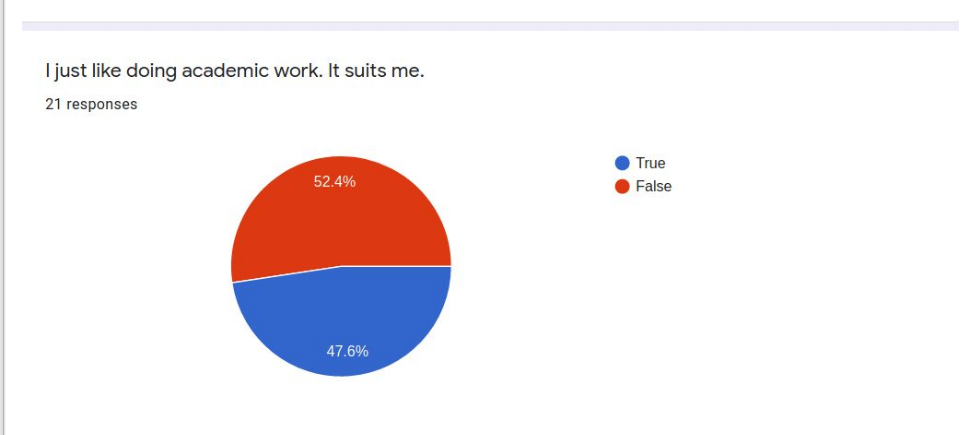
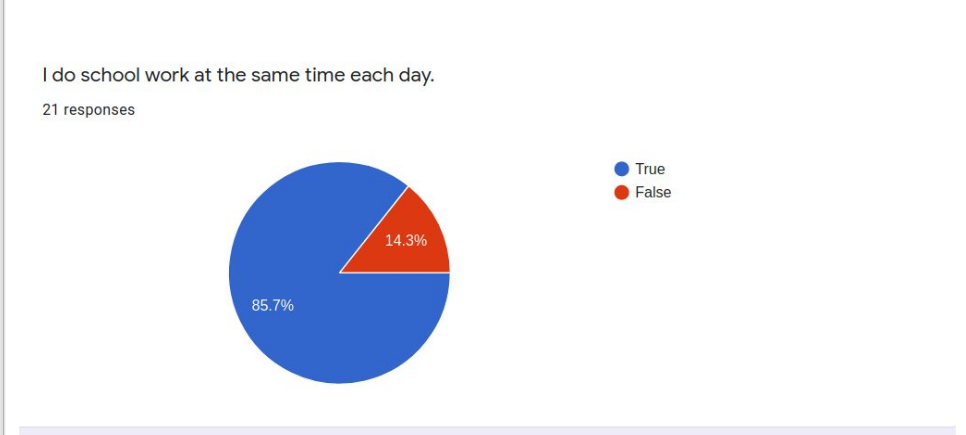
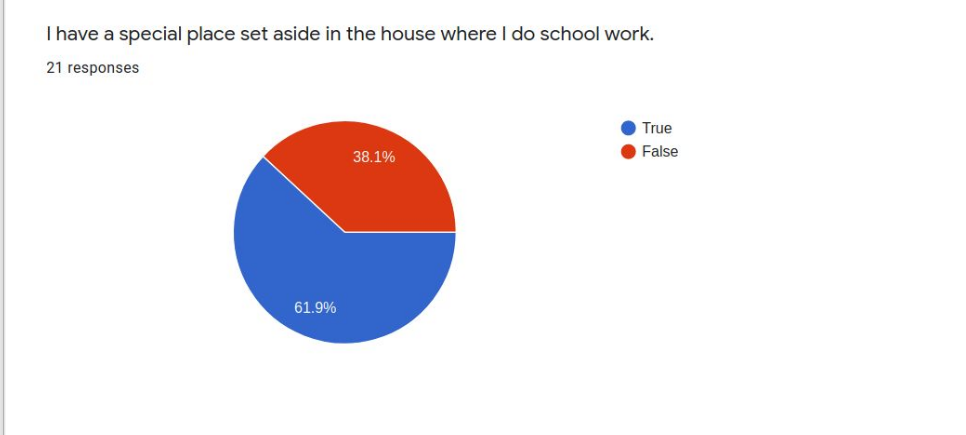
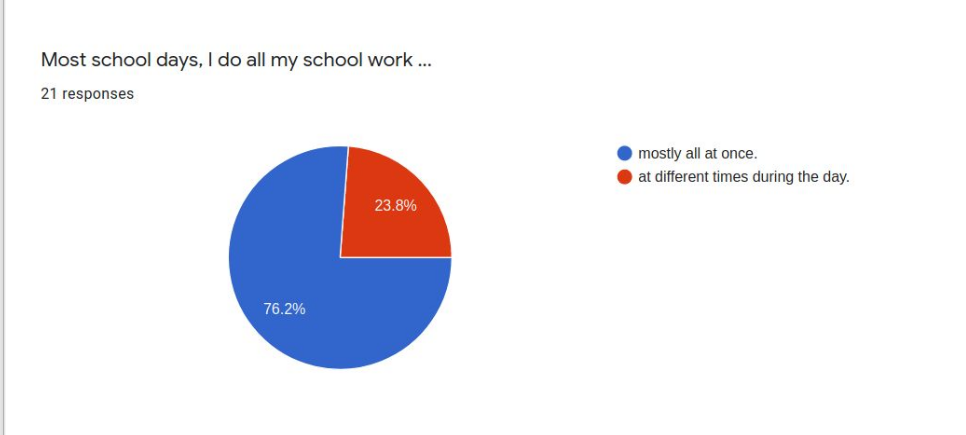
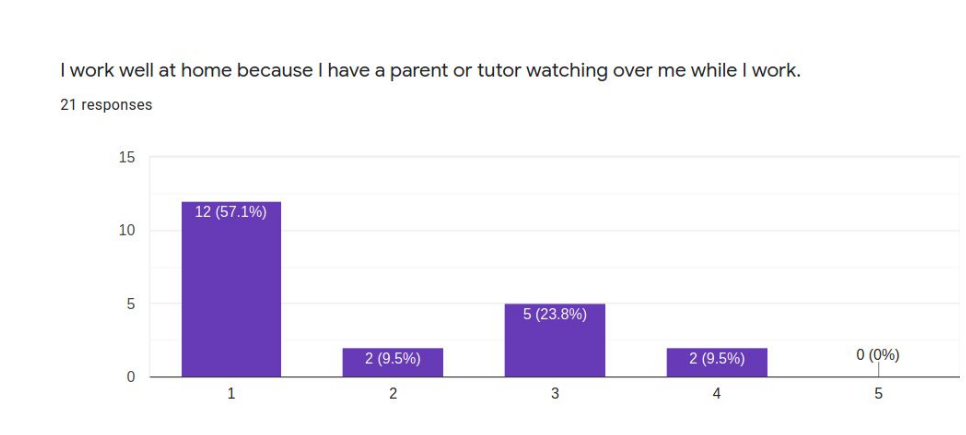
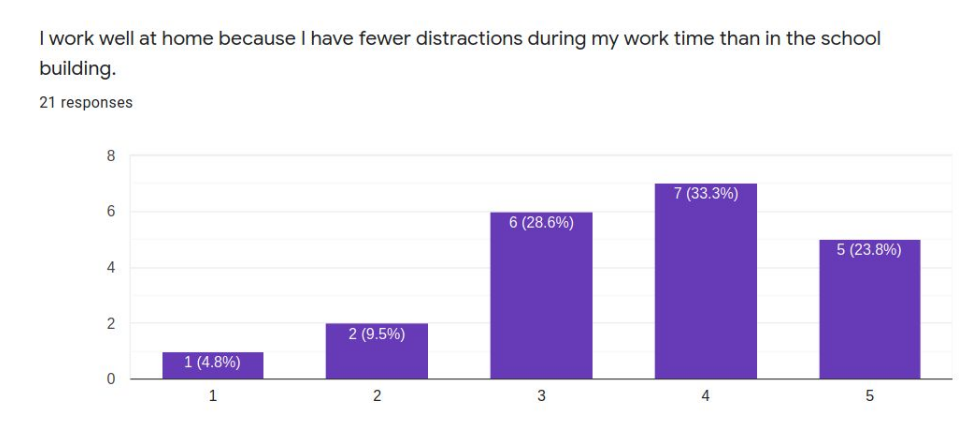
Twenty-one respondents to a survey asking successful online learners to report on the “secrets” of their success collectively present a profile of the student who will likely do well in asynchronous distance learning conditions. These students are very self-directed, seldom needing much parent intervention or supervision. Most like working online because there are fewer distractions than in school and they can work on their own schedules and at their own pace. These students have a special place set aside for doing school work and mostly do their school work in one sitting rather than sporadically through the day. These students are not necessarily very academic-oriented in temperament and may not even prefer online learning because they miss their friends and teachers. When asked to advise their peers, common suggestions include ideas like planning out the working and break or recreation time, keeping checklists, and self-motivation strategies.
Besides answering my questionnaire, 14 of 21 respondents accepted my invitation to make suggestions for their peers about their secrets for online success. Their comments are as follows:
I think that it easier to get all of your work done during the same time because then that way you can have the whole afternoon to do whatever you want.
As the Nike logo says “Just Do It”! I try not to put stuff off, however I wish it will be over soon so we can have summer and do other productive things with my family.
i have a system that i follow and i check all classes my email old emails at least 19 times a day
I try to give myself some time in the morning to wake up and have some time to myself, like an hour, then I start my day and work until lunch most times which I then take another hour or two to rest, finally I work until I am finished with little breaks and end most of the time right before dinner. I would say just try to get it done early then you could look forward tp having the rest of the day and if you get ahead then at the end of the week you could possibly have friday off, like I do. Also, just try and not get distracted and if you need to tell your siblings/parents/guardians you need quiet, my mom has learned that she can’t talk to me when I am doing school.
Something that motivates me is when I can take a 5-10 minute break between each subject. I use my RC car for this. While it is charging (it usually takes 45 minutes to charge) I do some work, and when it is done (it has a 10 minute run time) I go out and drive it.
I find that it helps to have a list of what I have to do and when they are due. This helps me to prioritize and not stress out as much about my work. I also tend to do my work in the morning. This way I have time to do my work and I can get it all done early. If I forget about an assignment, this also allows me to do it before it is due.
i just think that after i do all my work i can go out an do anything i want the rest of the day so i use that to motivate me
having parental involvement keeps me on task or i wouldn’t stay on task. My parents also checking power school regularly. I do struggle because i’m not getting as much assistance as i would during school.
Make sure to hunker down and just do your schoolwork. try to follow pretty much the same schedule every day and not get into a mindset of “I have all day to finish”, because chances are you’re just gonna keep on putting it off.
Well about the distractions. The main distraction I have at home and not school is food. Now that I am at home there are lots of food breaks.
I think a schedule is really important. Not only does it limit the amount of distractions in the day, but allows you to get through your work without missing anything or falling behind. I was home schooled before I came hear, and sometimes it’s nice to set apart time where you can watch a show or a play a game or something, that way you don’t feel as inclined to take a break in the middle of your work. That’s all the advice I got! 🙂
‘m getting better grades doing the online learning, but I don’t really like it because I’m not getting the same interactions with teachers and friends that I can get when I’m physically in school.
For me, I do a few hours of school work in the morning and then a few hours of it in the afternoon. I always take about an hour or two for a break in between those times. That break is very nice, and relaxing. I either go for a walk, or try to do another activity that is not school related. I find if I do not take that break, I get too overwhelmed. Questions 2 and 3: My parents check up on me, to see how I am doing. But they do not watch over me. Also, my parents trust that I am getting all the school work in on time, so they do not enforce too many rules, because I stay on top of it myself.
Fully functional and reliable automated “AI” grading of essays is a long way off yet and well beyond the computing capability available in typical secondary school classrooms. However, useful steps in that direction are well within reach, particularly for working within the domain of limited vocabulary and composition skills that constitute the typical proficiency level of students in grades six through twelve. High school social studies teachers in New York State assess student essays using a grading rubric provided by the State Education Department. One dimension of this rubric is to assess the relative degree of “analytic writing” versus descriptive. Students whose essays are more analytical than descriptive have a work of greater value. The artificially intelligent grading program at InnovationAssessments.com estimates the grade of a student writing sample by comparing it to a number of models in a corpus of full credit samples. With a view to developing an algorithm that better imitates human raters, this paper outlines the data and methods underlying an algorithm that yields an assessment of the “richness of analysis” of a student writing sample.
Measuring “Richness” of Analysis in Secondary Student Writing Samples
The New York State generic scoring rubrics for high school social studies Regents exams, both for thematic and document-based essay1, value student expository work where the piece “[i]s more analytical than descriptive (analyzes, evaluates, and/or creates* information)” (Abrams, 2004). A footnote in the Generic Grading Rubric states: “The term create as used by Anderson/Krathwohl, et al. in their 2001 revision of Bloom’s Taxonomy of Educational Objectives refers to the highest level of the cognitive domain. This usage of create is similar to Bloom’s use of the term synthesis. Creating implies an insightful reorganization of information into a new pattern or whole. While a level 5 paper will contain analysis and/or evaluation of information, a very strong paper may also include examples of creating information as defined by Anderson and Krathwohl.”
Anderson and Krathwohl (2002), in their revision of Bloom’s Taxonomy, define analysis thus:
4.0 Analyze – Breaking material into its constituent parts and detecting how the parts relate to one another and to an overall structure or purpose. 4.1 Differentiating 4.2 Organizing 4.3 Attributing
One of the ways that students analyze is to express cause and effect relationships (Anderson and Krathwohl’s “4.3 Attributing”). It is possible using natural language processing techniques to identify and examine cause and effect relationships in writing samples using lexical and syntactic indicators. Taking a cue from the New York State rubric, one could judge that a student writing sample is more “richly analytical” if it “spends” more words on cause and effect proportionate to the entire body of words written.
Identifying and Extracting Cause and Effect Relationships using Natural Language Processing
With regard to identifying cause-effect relationships in natural language, Asghar (2016, p. 2) notes that “[t]he existing literature on causal relation extraction falls into two broad categories: 1) approaches that employ linguistic, syntactic and semantic pattern matching only, and 2) techniques based on statistical methods and machine learning.” The former method was selected for this task because the domain is limited to secondary level student writing samples and they use a limited variety of writing structures. Previous work studying this issue yielded better results in domain-specific contexts (Asghar, 2016) and tagging sentences containing cause-effect relationships in this context should be within reach to a high degree of accuracy.
The software is written in Perl. The following process is applied to the student writing sample for analysis:
The text is “scrubbed” of extra consecutive spaces, HTML tags, and characters outside the normal alphanumeric ASCII range.
The Flesch-Kincaid text complexity measure is calculated.
The text is “lemmatized”, meaning words that have many variations are reduced to a root form (i.e., “is, am, are, were, was” etc. are all turned to “be”; “cause, caused, causing” etc. are all turned to “cause.”)
The text is “synonymized”, meaning words are changed to a single common synonym. The text is separated into an array of sentences and all words are tagged by their part of speech.
A variety of lexical and syntactic indicators of cause-effect are used in pattern matching to identify and extract sentences which include a cause-effect relationship into an array.
The resulting array of cause-effect relationship sentences are converted into a “bag of words2” without punctuation. Stop words are removed. All words are “stemmed”, meaning variations on spelling are removed.
Finally, both the original text and the array of cause-effect relationships are reduced further to a bag of unique words.
At this point, the computer program compares the bags of words. The resulting percentage is the proportion of unique words spent on cause-effect out of the total number of unique words. Recall that these are “bags of words” which have been lemmatized, synonymized, stemmed, and from which stop words have been removed.
Limitations of this Method
There are ways to express cause-effect relationships in English without using lexical indicators such as “because”, “thus”, “as”, etc. For example, one could express cause and effect this way: It was raining very heavily. We put on the windshield wipers and we drove slowly.
“Putting on the wipers” and “driving slowly” are caused by the heavy rain. There are no semantic or lexical indicators that signal this. There are many challenges dealing with “explicit and implicit causal relations based on syntactic-structure-based causal patterns” (Paramita, 2016). This algorithm does not attempt to identify this kind of expression of cause-effect. Prior research in this area has shown limited promise to date (Mirza, 2016, p. 70).
Cause-effect is only one way to analyze. Differentiating (categorizing) and organizing (prioritizing, setting up a hierarchy) should also be addressed in future versions of this software. A student could compose a “richly” analytical piece without using cause-effect, although in this writer’s experience cause-effect is the most common expression in writing of people in this age group.
Analyzing a Corpus of Student Work
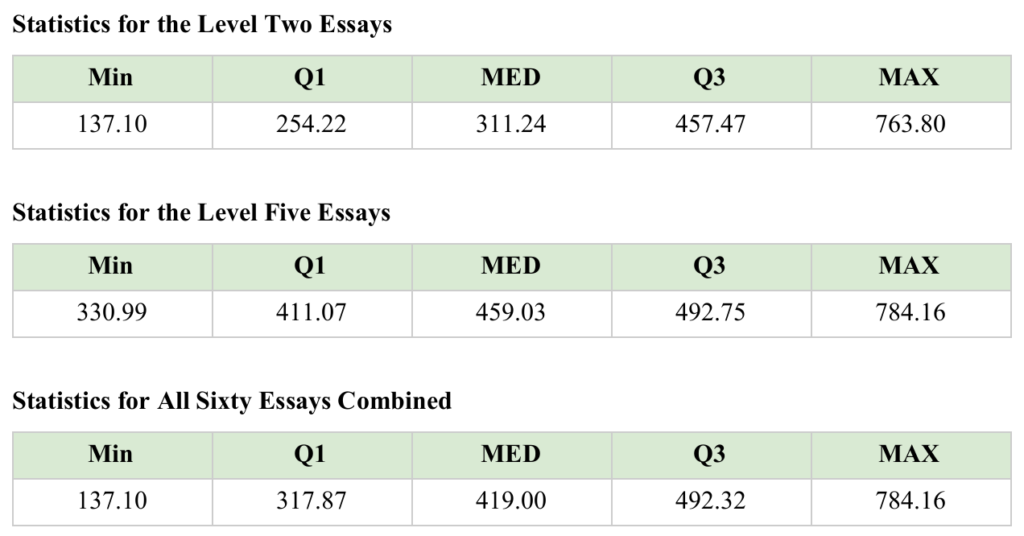
The New York State Education Department provides anchor papers for the Regents exams so that raters can have models of each possible essay score on a scale of one to five. Anchor papers are written by actual students during the field testing phase of the examination creation process. Sixty such anchor papers were selected for use in this study from collections of thematic and document-based essays available online at the New York State Education Department website archive (https://www.nysedregents.org/GlobalHistoryGeography/). Thirty came from papers identified as scoring level five and thirty scoring level two. Essays scoring five are exemplary and rare. Papers scoring two are “passing” and represent the most common score. Essays are provided online in PDF format. Each one was transformed to plain text using GoogleDrive’s OCR feature. Newline characters were removed as was any text not composed by a student (such as header information). This constitutes the corpus.
The computer program analyzed each sample and returned the following statistics: number of cause-effect sentences found in the sample, the count of unique words “spent” on cause-effect relationships in the whole text, the count of unique words in the entire text, the percentage of unique words spent on cause-effect, the seconds it took to process, text complexity as measured by the Flesch-Kincaid readability formula, and finally a figure that is termed the “analysis score” and is intended to be a measure of “richness” in analysis in the writing sample.
An interesting and somewhat surprising finding came in comparing the corpus of level two essays to those scoring a level five. There was no real difference in the percentage of unique words students writing at these levels spent “doing” analysis of cause-effect. The mean percent of words spent on cause-effect relative to the unique words in the entire text was 46% in level five essays and 45% in level twos. There were no outliers and the standard deviation for the level fives was 0.9; for the level twos it was 0.13. Initially, it seemed that essays of poor quality would have a much different figure, but this turned out not to be the case. What made these level two papers just passing was their length and limited factual content (recall that analysis is only one dimension on this rubric).
Text complexity is an important factor in evaluating student writing. The Flesch-Kincaid readability formula is one well-known method for calculating the grade level readability of a text. In an evaluation of the “richness” of a student’s use of analysis, text complexity is a significant and distinguishing feature. The “analysis score” is a figure intended to convey that combination of text complexity and words spent on cause-effect type analysis. This figure is calculated by multiplying the percentage of unique words spent on cause-effect by 100, and then multiplying by the grade level result of the Flesch-Kincaid formula. This measure yielded more differentiating results. In order to discover ranges of normal performance based on these models, the following statistics were calculated for each data set: lowest score (MIN), first quartile(Q1), median(MED), third quartile(Q3), and highest score(MAX).
If this corpus of sixty essays can be considered representative, then the ranges can be considered standards in assessing the richness of secondary level student analysis in a writing sample. These figures can be used to devise a rubric. On a scale of one to four where four is the highest valued sample, the following ranges are derived from the combined statistics of all sixty essays:
Incorporation of Cause-Effect Assessment into AI-Assisted Grading
The artificially-intelligent grading assistance provided subscribers at InnovationAssessments.com, to date, estimates grades for student composition work based on a comparison of eleven text features of the student sample from a comparison with the most similar model answer in a corpus of one or more model texts. In cases where expository compositions are valued higher for being “analytically rich”, incorporating this cause-effect function could refine and enhance AI-assisted scoring.
Firstly, the algorithm will examine the most similar model in the corpus to the student sample. If the analysis score of the model text is greater than or equal to 419, then it is assumed analysis is a feature of the response’s value. In this case, an evaluation of the “analytical richness” of the student’s work will be incorporated into the scoring estimate. Samples that are more analytical will have greater chances of scoring well.
Conclusion
An artificially intelligent grading program for secondary student expository writing that includes an evaluation of the richness of analysis in that text would be very valuable. Cause-effect statements are indicators of analysis. The algorithm described here identifies and extracts these sentences, processes them for meaningful analysis, and judges the quality of the student’s analysis with a number which incorporates a measure of the proportion of words spent on analysis and text complexity. An analysis of sixty samples of student writing yielded a range of scores at four levels of quality for use in artificial grading schemes. While this algorithm does not detect all varieties of cause-effect relationships nor even all types of analysis, its incorporation in already established artificial scoring programs may well enhance the accuracy and reliability of the program.
Asghar, N. (May 2016). Automatic Extraction of Causal Relations fromNatural Language Texts: A Comprehensive Survey. Retrieved from https://arxiv.org/pdf/1605.07895.pdf.
Mirza, Paramita. (2016). Extracting Temporal and Causal Relations between Events. 10.13140/RG.2.1.3713.5765 .
Sorgente, A., Vettigli G., & Mele F. (January 2013) Automatic extraction of cause-effect relations inNatural Language Text. Retrieved from http://ceur-ws.org/Vol-1109/paper4.pdf .
My first experience with asynchronous discussion forums came in courses I was taking myself online through Empire State College a number of years ago. Many readers will recognize the assignment: given a prompt, students are to post their response and then reply to the responses of a number of other students in the class. Typically, there was a deadline by which these discussions had to take place. I liked the exercise and I found it useful to address the course material.
Promoters of asynchronous discussion forums point out rightly that this task brings greater participation than face-to-face class discussions do. Whereas in the latter situation, participation may be dominated by an extroverted few or limited in other ways, the online forum brings everybody in. Asynchronous discussion leave time for research and reflection that is not practical in the face-to-face class. There are some practical considerations for students at the middle and high school level that are not usually issues at the college level.
My Experience
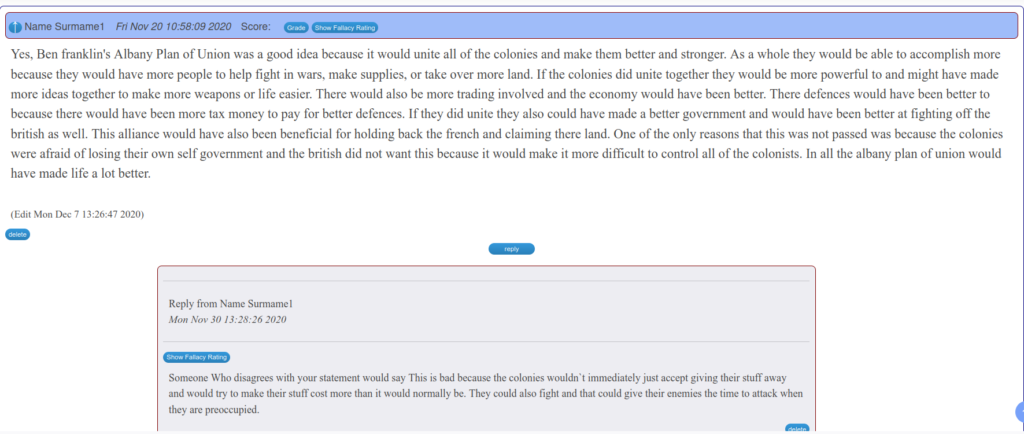
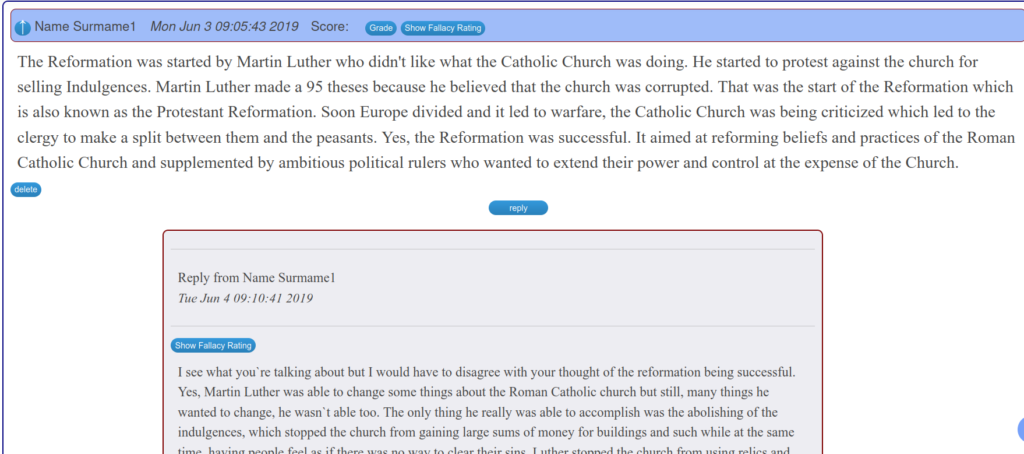
I used asynchronous form discussions in my middle and high school social studies classes for a decade. This occurred in each unit of student. In my context, students were assigned a persuasive prompt to which they were expected to take a position and post two supporting reasons. Next, they were assigned to present the opposing view to another student (even if it did not match their actual personal views), and finally they were to defend their original position in reply to the student who was assigned to present the opposing view to themselves.
Sample 7th Grader Exchange
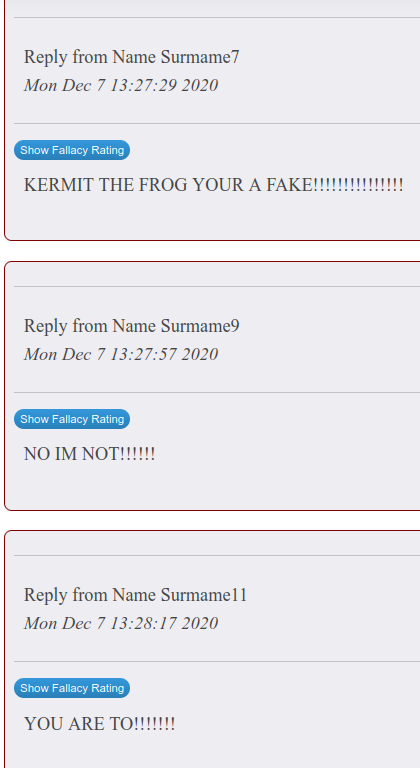
Seventh and eight graders needed training right off the bat, naturally. Accustomed to social media, their early contributions were vapid and full of emojis and “txt” language. It was important to remind them that this was a formal enterprise and that standard English conventions held. It was often difficult to get them to elaborate their ideas toward the 200-word goal set for their opening post.
Not the kind of thing I as looking for!
I was working in a small, rural school where I would have the students from grades seven through ten, so I could see their work develop over the years.
By end of 9th grade, posts became more sophisticated
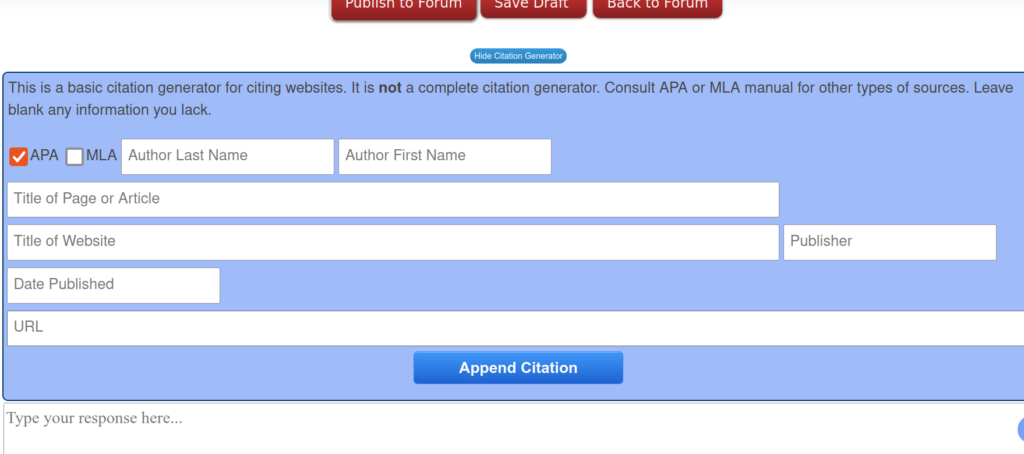
I found it to be a good practice to offer the highest marks to those who provided evidence and cited a source. I coded a citation generator right in the forum app to encourage this.
Grading the Posts
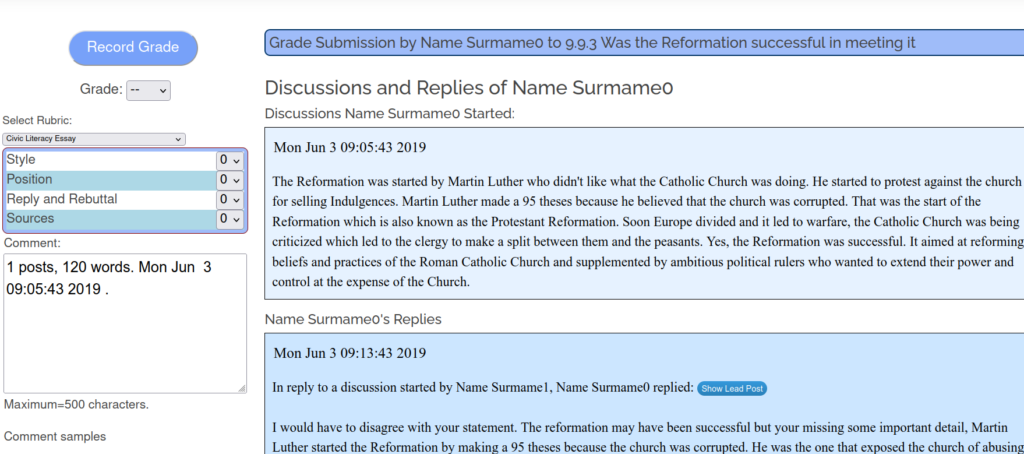
Scoring these can be labor intensive for no other reason than the layout of the forum itself. The page is designed for reading and responding, but this does not work well for scoring because there is too much scrolling and searching necessary to view posts and replies.
The scoring app makes it easy for the teacher to view the rubric, the student’s posts, and their replies to others in one place. Analysis tools lets the teacher see how many posts, when they were made, and even the readability level of the contributions.My early discussion grading rubric.The grading rubric I adopted later on.
Practical Issues
The main problem I encountered in this assignment was that students would forget to complete it at first. I resolved this by assigning it in class and giving time. For example, on the first day I would present the prompt and instruct students to post their positions that class period before continuing with the day’s other work. The following day, students would have time to post their replies and finally a third day they would post their defense.
Another issue that came up was getting everyone the needed number of replies. Some posts would attract more replies than others. Some students needed a reply so they could offer defense. The solution was to modify the assignment and declare that, once one has posted, one is obliged to offer the opposing view to the person above in the forum feed.
Interestingly, these assignments also led to face-to-face spontaneous class discussions, sometimes with me and sometimes with a group. Although this may have been somewhat distracting for students in the class working on other things, we found some compromise time to allow these spontaneous interactions to proceed without disrupting the other work much. These were golden opportunities, conversations of enormous educational benefit that are so hard to artificially initiate and encourage.
I came to regard the discussion each unit as a sort of group persuasive writing effort. I included training in grade eight in persuasive writing and logical fallacies. The discussion app here at Innovation has a feature which allows readers to flag posts as committing a logical fallacy.
The Innovation Discussion Forum App is a 21st Century Learning Space
Guardrails: The app lets the teacher monitor all conversations and to delete problematic ones.
Training Wheels: The teacher can attach a grading rubric and sample posts. I used to post first under a pseudonym to whom the first student could reply. Additionally, weaker students can peruse the posts of stronger students in an effort to get a clear picture of the kinds of opinions that can be had on the issue.
Debriefing: Debriefing is easily achieved by projecting the discussion screen on the from board. Students posts in this task are not anonymous.
Assessment and Feedback: The scoring app is very efficient and highly developed from years of use. The teacher can view all pf the student’s posts and replies without having to scroll across the entire platform. Analysis tools reveal the readability of the text, how much they wrote, how analytical it is.
Swiss Army Knife: The discussion app lends itself well to more in-depth persuasive writing assignments such as an essay.
Locus of Data Control: The student chat submissions are stored on a server licensed to the teacher’s control. Commercial apps such as FaceBook and Twitter may be less dedicated to the kinds of privacy and control exigencies of education.
Ideas in Closing
Asynchronous discussions are great – my students and I enjoyed these tasks. It is my view that higher level thinking demanded by persuasion and debate (Bloom’s evaluation level of the cognitive domain) really enhance long-term memory of the content. I cannot emphasize enough the value of these kinds of higher-order task. Working in a 21st century learning space promotes the participation of everybody.
Research and development of software to harness artificial intelligence for scoring student essays has many significant obstacles. Using machine learning techniques requires massive amounts of data and computing power far beyond what is available to the typical secondary public school. The cost and effort to devise such technology does not seem to be juice worth the squeeze, since it is still more time efficient and cost effective to just have a human do the job. However, the potential exists to devise AI-assisted grading software whose purpose is to increase the speed and accuracy of human raters. AI grading that is “assisted” applies natural language processing strategies to student writing samples in a narrowly defined context and operates in a mostly “supervised” fashion. That is, a human rater activates the software and may make scoring judgments with the advice provided by the AI. A promising area for this, more narrowly contextualized application of artificially intelligent natural language processing, is in scoring summaries and short answer tests. This also poses interesting possibilities for automated coaching for students while they write. This study examines a set of algorithms that derives a suggested score for a secondary level student summary and short answer test response by comparing a corpus of model answers selected by a human rater with the student work. The human rater stays on duty for the scoring process, adding full credit student work to the corpus such that the AIs is trained and selecting student scores.
Features of Text for Comparison
The AI examines the following text characteristics to evaluate a student work by comparison to one or more models:
“readability” as determined by the Flesch-Kincaid readability formula
the percent difference in number of unique words after pre-processing. “Preprocessing” refers to text that has been scrubbed of irrelevant characters like HTML tags and extra spaces, has been lemmatized, synonymized, and finally stemmed.
intersecting noun phrases
Jaccard similarity
cosine similarity of unigrams
cosine similarity of bigrams
cosine similarity of trigrams
intersecting proper nouns
cosine similarity of T-score
intersecting bigrams as percent of corpus size
intersecting trigrams as percent of corpus size
analysis score2
The program first compares the student text to each model using cosine similarity of n-grams. The most similar model in the corpus is then compared to the student work. Four hundred and twenty-six short answer questions that had been scored by a human rater were compared using the algorithm. From these results was developed scoring ranges within each text feature typifying scores of 100, 85, 65, 55, and 0. Outliers were removed from the dataset. Next, sets of student summaries were scored using the ranges for each text feature and the program’s scoring accuracy was monitored. With each successive scoring trial, the profiles were adjusted, sometimes more intuitively that methodically, until over the course of months the accuracy rate was satisfactory.
When analyzing a student writing sample for scoring, the score on each text feature is compared to the profiles and the program keeps a tally of matches for each scoring category (100, 85, 65, 55, and 0). The “best fit” is the first stage of suggested score. Noun phrases, intersecting proper nouns, and bigram cosine were found to correlate most highly with score matching the human rater, so an additional calculation is applied to the profile scores to weight these factors. Next, a set of functions calculates partial credit possibilities for scores in the category of 94, 76 and 44 using statistics from the data analysis of the original dataset of 426 samples. Finally, samples where analysis are important in the response have their score adjusted one final time.
The development of the scoring ranges for text features proceeded somewhat methodically and at times more intuitively or organically. Over the course of months, when error patterns in AI scoring became apparent, adjustments were made to improve performance. Natural language processing, even at this basic level, is very demanding on computer memory and processing resources. At this writing, the server running this software has 6GB of RAM and work is often being done on the code to reduce processing time. One strategy is to store both “raw” and processed versions of the student work products as they are written so that processing time can be shortened at the end. the corpus of model responses is also saved in this way.
Training the AI
Upon creation of an assignment, the teacher can save model responses to the corpus. Once students have completed the assignment, the teacher can begin by reviewing and scoring the work product of students who usually score full credit. Upon confirming that these are indeed full credit models, the teacher can click a button to add the student sample to the corpus of model answers. The software limits the teacher to five models in short answer testing and seven models in composition assessment.
Once trained, the teacher can run the scoring algorithm on each student submission. At this writing, processing takes about nine seconds on average per sample, depending on the text size. This program works best for assignments where there is a narrow range of full credit responses. Its primary purpose is to score writing samples by comparing to a limited number of full credit responses. Its strength is in recognizing similar meaning across texts in varying ways to say the same thing. This program does not assess spelling or technical / mechanical writing conventions, although it does rely on student accuracy for scoring to the extent that adherence to certain conventions are necessary for the program to operate. Examples: proper noun count requires that students capitalize them; sentence count requires that students apply standard rules of punctuation.